AI Providers (FiestaBot setup)
FiestaBot is FiestaBoard's built-in AI assistant. Click AI Assistant in the sidebar (the Sparkles icon) to open the chat panel, then describe what you want in plain language — FiestaBot drafts and edits board pages through conversation, and can also install plugins, update settings, and manage schedules.
FiestaBoard ships without any bundled LLM credentials. You bring your own provider, your own API key, and your own model list. There is no FiestaBoard-hosted AI proxy.
Two protocols are supported out of the box:
- OpenAI-compatible chat completions — one-click presets for OpenAI, OpenRouter, Groq, DeepSeek, Mistral, Together AI, and Fireworks AI, plus local servers Ollama, LM Studio, llama.cpp, and vLLM. Any other OpenAI-compatible endpoint works too — just paste the base URL.
- Anthropic Messages API — direct access to
api.anthropic.comusing a Claude API key.
Click any preset pill in Settings → AI Providers to autofill the provider name, base URL, and protocol — then paste your key and add the model ids you want to use.
The preset list is intentionally limited to providers that fully
honor the OpenAI response_format: json_object field that the page
generator relies on. Other services (Google Gemini's OpenAI shim,
xAI Grok, Perplexity Sonar, Cerebras, Nvidia NIM, DeepInfra, …) can
still be used by entering the base URL by hand — just be aware that
strict JSON mode may need the prompt-only fallback to kick in.
Choosing a provider
Not sure which one to pick? Here's the short version.
We recommend OpenRouter for most users
OpenRouter is our suggested starting point. It's a single API and a single API key that gives you access to hundreds of models from OpenAI, Anthropic, Google, Meta, Mistral, DeepSeek, and others — including most of the open-weight models — with pay-as-you-go billing and no per-provider account juggling. You can swap models from the FiestaBot model dropdown without re-entering credentials.
Disclosure: We recommend OpenRouter because it works well, not because we get paid to. FiestaBoard receives no referral fees, kickbacks, affiliate commissions, or other compensation from OpenRouter — there's no
?ref=link in our docs and no partner agreement of any kind. We just like the product. If you'd prefer a direct relationship with one provider, any of the other presets works equally well.
When to pick something else
- You already pay for OpenAI / Anthropic / Mistral / etc. — use the matching preset and your existing key. No reason to add an OpenRouter middleman.
- You want the lowest possible latency — Groq and DeepSeek are typically faster than OpenRouter's pooled routing.
- You want everything to stay on your own hardware — pick a local preset (Ollama, LM Studio, llama.cpp, vLLM). Note the caveats about smaller models and JSON adherence below.
- You're in the EU and care about data residency — Mistral is EU-hosted.
Quick setup with preset pills
In Settings → AI Providers, the Quick presets row gives you one-click pills for every supported provider, grouped into Cloud (OpenAI, OpenRouter, Anthropic, Groq, DeepSeek, Mistral, Together AI, Fireworks AI) and Local (Ollama, LM Studio, llama.cpp, vLLM). Clicking a pill auto-fills:
- the Name field (so you don't have to think of a label),
- the Base URL (so you don't have to look it up), and
- the Protocol (OpenAI-compatible vs. Anthropic Messages).
You only have to paste your API key and add the model ids you want
to use. For local servers running on the same machine as
FiestaBoard, the preset URLs already point at the right localhost
port — just start your server and click Test connection.
Configuration
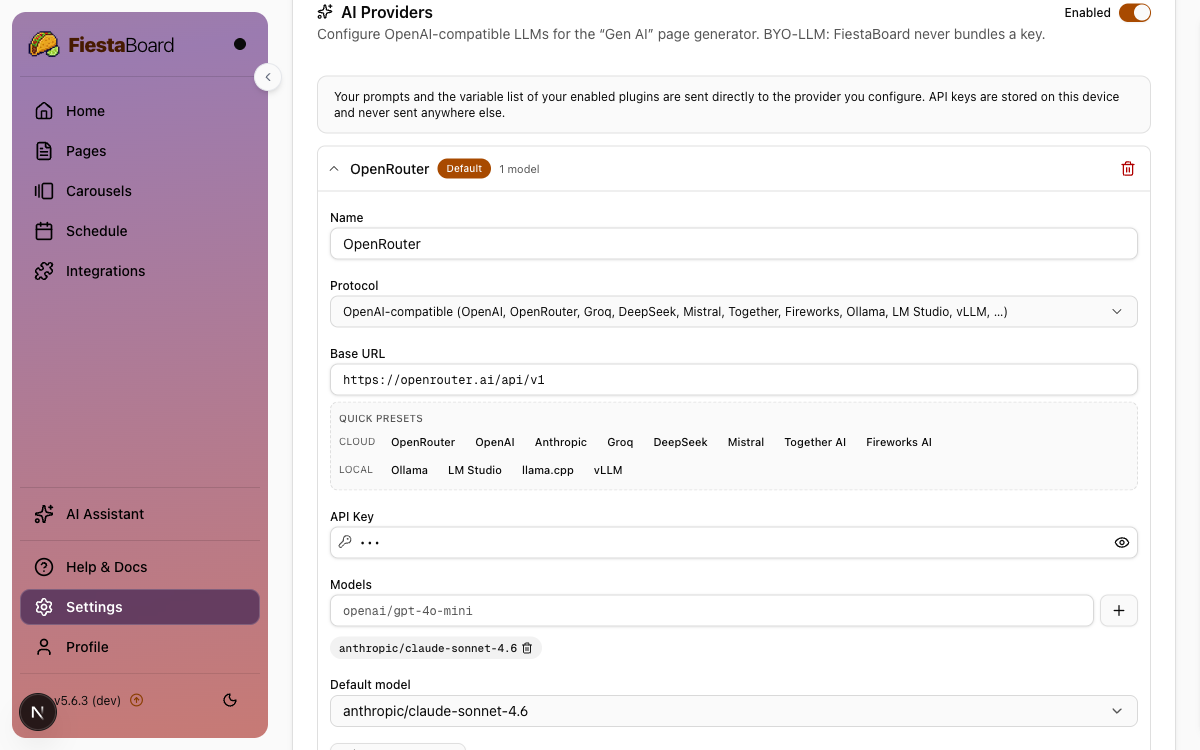
- Open Settings → AI Providers.
- Toggle the top switch to Enabled.
- Click Add provider and fill in:
- Name — any label, e.g.
OpenRouterorClaude. Auto-filled when you click a preset pill. - Protocol — pick
OpenAI-compatibleorAnthropic. The quick-pick buttons below also set this for you. - Base URL — the API root, e.g.
https://openrouter.ai/api/v1orhttps://api.anthropic.com/v1. One-click preset pills cover OpenRouter, OpenAI, Anthropic, Groq, DeepSeek, Mistral, Together, and Fireworks, plus local servers Ollama, LM Studio, llama.cpp, and vLLM. - API Key — paste the key. It is stored on this device's
data/config.jsonand is masked (***) on read. - Models — type each model id and press Enter or click
+(e.g.openai/gpt-4o-mini,claude-3-5-sonnet-20241022). - Default model — picked automatically once you add at least one model.
- Name — any label, e.g.
- (Optional) Click Test connection to send a one-token smoke test and confirm credentials and connectivity.
- Click Save changes.
If you configure more than one provider, mark one as the default using the Make default button. FiestaBot will use the default provider unless you pick another from the dropdown in the chat panel.
Recommended models
These all work well with the FiestaBoard prompt format:
| Provider | Protocol | Model | Notes |
|---|---|---|---|
| OpenRouter | OpenAI | openai/gpt-4o-mini | Cheap, fast, reliable JSON output. |
| OpenRouter | OpenAI | anthropic/claude-3.5-sonnet | High-quality, slower. |
| OpenAI | OpenAI | gpt-4o-mini | Same as via OpenRouter. |
| Anthropic | Anthropic | claude-3-5-sonnet-20241022 | Direct, no OpenRouter markup. |
| Anthropic | Anthropic | claude-3-5-haiku-20241022 | Cheaper, fast. |
| Groq | OpenAI | llama-3.3-70b-versatile | Very low latency. |
| DeepSeek | OpenAI | deepseek-chat | Cheap, capable. |
| Mistral | OpenAI | mistral-large-latest | EU-hosted option. |
| Together AI | OpenAI | meta-llama/Llama-3.3-70B-Instruct-Turbo | Hosted open weights. |
| Fireworks AI | OpenAI | accounts/fireworks/models/llama-v3p3-70b-instruct | Hosted open weights. |
| Local Ollama | OpenAI | qwen2.5:14b-instruct or larger | Needs a model that follows JSON. |
| Local LM Studio | OpenAI | A 14B+ instruction-tuned model | Same JSON-adherence caveat. |
Smaller (≤ 7B) local models often struggle to emit valid JSON for the FiestaBoard schema; if you see frequent "Could not parse JSON" errors, switch to a larger or instruction-tuned model.
Privacy
Each time you send a message, FiestaBot sends to the provider you configured:
- The system prompt (board dimensions, character set rules, JSON schema, and available template functions).
- Your message.
- The variable list of all enabled plugins (names + descriptions
- max widths). This may include data such as transit station IDs or location names that you have configured.
- Up to a handful of example pages drawn from plugin manifests.
- The current page being edited (when a page is open in the editor — FiestaBot always has context of what you're working on).
- Context about your pages, schedules, carousels, and installed plugins (names and IDs only, not content).
API keys are stored locally in data/config.json and never sent to
any FiestaBoard-hosted service.
Limitations
- Two protocols supported: OpenAI-compatible chat completions
(presets cover OpenAI, OpenRouter, Groq, DeepSeek, Mistral,
Together, Fireworks, Ollama, LM Studio, llama.cpp, and vLLM), and
the Anthropic Messages API. Other providers (Google Gemini, xAI
Grok, Perplexity, Cerebras, DeepInfra, Nvidia NIM, Cohere, …) can
be reached today through OpenRouter, by entering the base URL
manually (some don't strictly honor JSON mode), or by registering a
new entry in
src/ai/protocols.py. - No image/vision input.
- FiestaBot never saves pages, installs plugins, or changes settings without showing a confirmation step first — you always have the final say.
- A modest per-process rate limit applies to page generation requests to protect against runaway clients (1 second between calls, 2 concurrent).
Troubleshooting
AI Assistant doesn't appear in the sidebar You need at least one provider configured in Settings → AI Providers with the top toggle set to Enabled. The sidebar item only appears once a provider exists.
"Could not parse JSON" or repeated empty results
The model isn't returning valid JSON for the board schema. Switch
to a stronger model (e.g. gpt-4o-mini or
claude-3-5-sonnet-20241022) or one explicitly tuned for
instruction following.
Test connection fails
Double-check the Base URL (it should usually end in /v1),
verify the API key has not been revoked, and confirm the model id
exists for that provider.